Иногда они возвращаются — просьбы помочь. «Тыжпрограммист» и другие ярлыки, которые так любят клеить твои коллеги, совсем не те ачивки, которые ты хотел получать на службе. Но разве мы откажем нашим офисным друзьям в небольшой просьбе?
Покой нам только снится
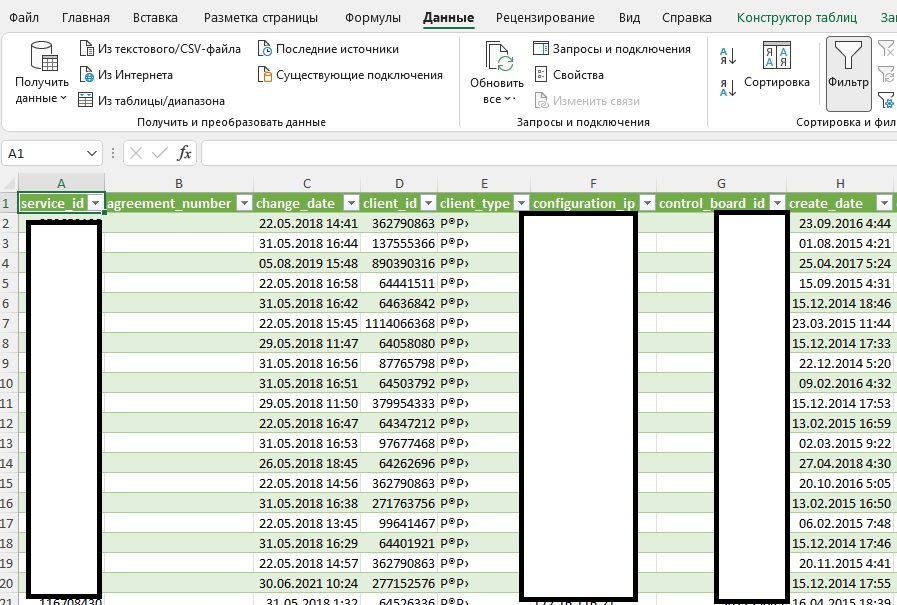
Итак, у нас есть некие сырые данные. Либо это парсинг чего-либо, либо просто набор каких-то символов, цифр, etc. Возможно, это выгрузка это будет выгрузка CSV, но в любом случае нам нужно сделать из этого нормальную таблицу в Excel — со столбцами и строками. Исходник:
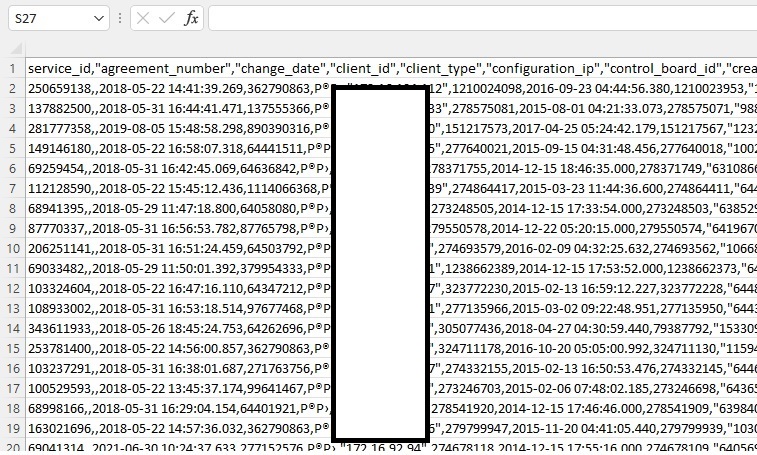
Как мы будем это делать? Вне зависимости от того, в каком виде к вам попали эти данные — скопируйте их в текстовый документ, в блокнот или notepad++ (да, при большом объеме данных придётся подождать)
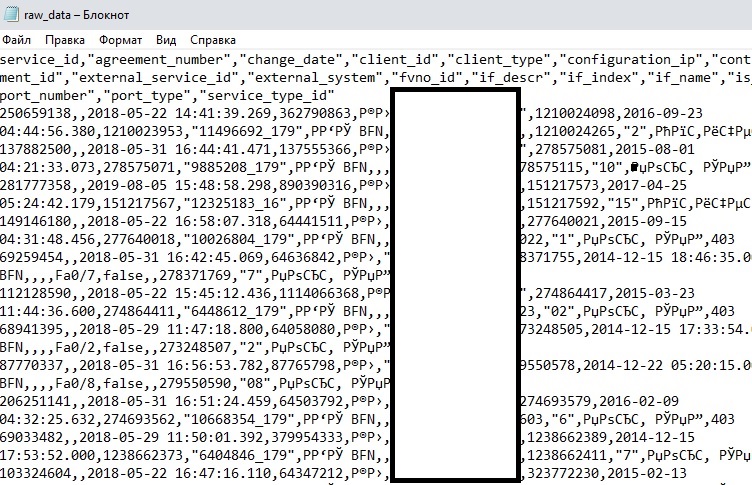
Важный момент конкретно в этом примере — наличие разделителя, т.е. запятая после каждого элемента данных. Он может быть любой, не обязательно именно запятая. Без него будет несколько сложнее.
Код
Будем работать с библиотекой Pandas, для работы с датафреймами. В переменную Excel записываем наш текстовый файл (если не писать путь до него, то он должен находится в одной папке со скриптом).
Далее вызываем метод чтения данных CSV с параметрами, где sep — это разделитель.
Зачем мы добавляем error_bad_lines=False в параметры? Если наш парсер не сможет обработать какие-то строки, то выдаст ошибку pandas.errors.ParserError: Error tokenizing data и выполнение скрипта прекратится. Чтобы этого избежать мы даём команду игнорировать ошибки при обработке.
Записываем в переменную список всех имён столбцов (column_indexes). Сбрасываем индексы (df.reset_index), удаляем первый столбец df.drop (если вам нужен дополнительный столбец ID, который идёт первым, то можете этого не делать, если нужны только оригинальные данные — оставляем код)
После чего подставляем (переименовываем) названия столбцов и записываем результат в Excel.
Полный код:
import pandas as pd
excel = 'raw_data2.txt'
df = pd.read_csv(excel, sep=',', error_bad_lines=False)
column_indexes = list(df.columns)
df.reset_index(inplace=True)
df.drop(columns=df.columns[0], inplace=True)
column_indexes = dict(zip(list(df.columns), column_indexes))
df.rename(columns=column_indexes, inplace=True)
df.to_excel('output_2.xlsx', 'Sheet1', index=False)
Можно ли это сделать с помощью Excel?
Теоретически — можно, если Power Query сможет разобрать, что написано в вашем файле. Делается это просто: в Excel переходим во вкладку «Данные» и блок «Получить и преобразовать данные«. Нажимаем на «Из текстового/CSV-файла«.
Выбираем текстовый документ с данными и механизм выдаст нам уже подготовленные данные:
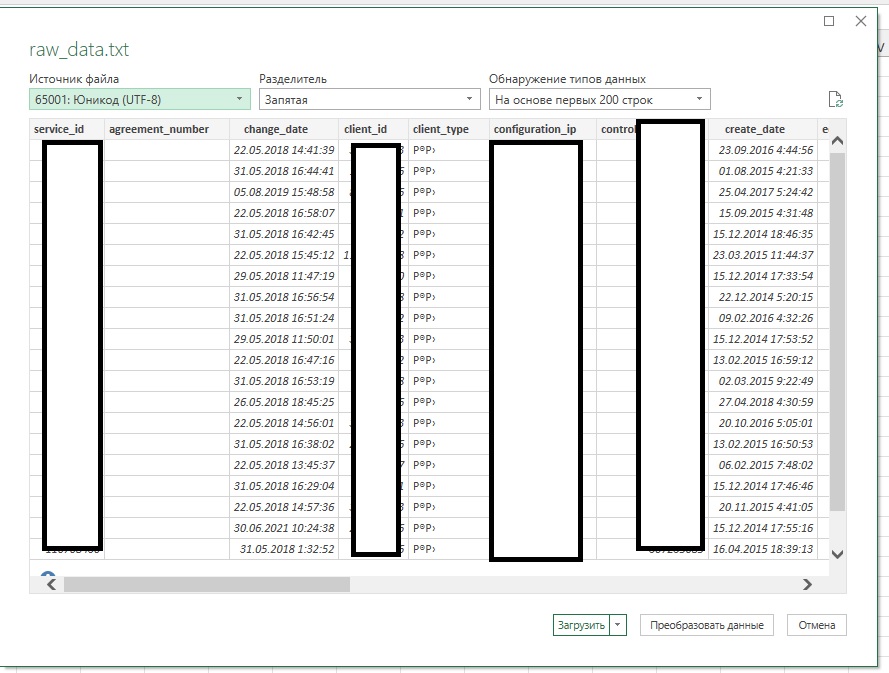
Нажимаем «Преобразовать данные» и получаем готовую таблицу (если всё ок просто нажмите «Загрузить и закрыть» в левом верхнем углу)